
Algoritmi allo specchio
La dama di Samuel, il mito di Narciso, il Mostro Aspirapolvere di John Lennon e il collasso del modello: il potere e il rischio di imparare da soli


Nei giorni immediatamente successivi all'uscita del post Arthur Samuel e la macchina che giocava a dama sul mio blog Mr. Palomar, ho riflettuto a lungo su una questione. Nel post raccontavo un episodio significativo del primo periodo dell’intelligenza artificiale, ovvero il successo del giocatore artificiale di dama sviluppato da Arthur Samuel. In particolare, sottolineavo come Samuel, per addestrare il suo modello, avesse adottato un approccio innovativo, destinato a diventare una delle varianti fondamentali del machine learning: l’apprendimento per rinforzo (reinforcement learning).
L’idea è piuttosto semplice: anziché fornire alla macchina esempi etichettati, sulla base dei quali l’algoritmo dovrebbe coltivare il proprio modello attraverso un processo di generalizzazione (l’approccio denominato supervised learning), si fa interagire l’algoritmo con un ambiente esterno, e gli si attribuiscono ricompense o penalità in base alle conseguenze delle azioni compiute.
Non è difficile immaginare come possano funzionare i due diversi paradigmi nel caso dei giochi da tavolo come la dama.
Nel supervised learning si mostrano alla macchina migliaia o milioni di configurazioni createsi nel corso di partite reali disputate da giocatori umani, e per ognuna si rivela all’algoritmo quale dei due giocatori ha vinto la partita. È ciò che è stato fatto, per esempio, nel progetto DeepChess. Generalizzando sulla base di questo dataset di esempi l’algoritmo costruisce un modello che gli permette di confrontare anche posizioni completamente nuove e di individuare la più favorevole, cioè quella più probabilmente associata a un esito vittorioso della partita.
Nei più celebri progetti di IA per giochi da tavolo, il reinforcement learning è stato spesso implementato attraverso il self-play: l’algoritmo viene fatto giocare migliaia o milioni di volte contro copie di sé stesso, senza insegnargli nulla preliminarmente e senza mostrargli in anticipo alcuna posizione storica etichettata. Questo fu il paradigma scelto da Samuel per il suo programma di dama, ma molti anni dopo ha rappresentato anche la base concettuale dei celebri progetti AlphaGo e AlphaZero sviluppati da Google DeepMind.
Al di fuori del mondo dei giochi da tavolo, l’apprendimento per rinforzo può essere applicato in molti modi, diversi dal self-play. Pensate a un’auto autonoma che viene messa in strada, a un braccio robotico che afferra oggetti reali, a un agente che fa trading sul mercato finanziario: le ricompense possono essere, rispettivamente, compiere un percorso senza incidenti, riuscire a eseguire le prese, ottenere un profitto.
Ma giocare contro sé stessi rappresenta un modo molto suggestivo per apprendere. In questi ultimi giorni ho pensato molto all’archetipo del doppio, molto ricorrente in ogni epoca e cultura: dal classico Narciso al Doppelgänger germanico, da Jekyll e Hyde a Dorian Gray e così via.

“Narciso”, attribuito a Caravaggio (olio su tela, Galleria Nazionale d'Arte Antica, Roma)
L’idea che si possa imparare soltanto guardandosi allo specchio, insomma, si innesta in una tradizione letteraria e mitologica molto antica. Si potrebbe parlare di narcisismo computazionale, ma, a ben vedere, non c’è soltanto il tema dello specchiarsi. Secondo me la differenza fondamentale rispetto agli altri approcci è che nel self-play la macchina non impara osservando il comportamento degli esseri umani e nemmeno interagendo con il mondo fisico. Nell’unsupervised learning la macchina osserva esempi reali, nel supervised learning riceve anche le etichette attribuite dagli operatori umani, nel reinforcement learning senza self-play si immerge completamente nella realtà esterna per imparare.
Qui no. L’algoritmo abita in un universo chiuso nel quale l’unico interlocutore è un proprio clone. Una sorta di apprendimento autarchico, di intelligenza solipsistica. I detrattori moderni dell’IA avrebbero molti motivi per gridare allo scandalo, o semplicemente per rimarcare la superiorità dell’intelligenza naturale contro queste forme disincarnate e autoreferenziali di intelligenza. Ma il fatto è che il self-play funziona, eccome. Svolge molto bene il proprio lavoro quando l’ambito da gestire è ben delimitato, come lo è un gioco da tavolo. Nella terminologia della teoria dei giochi, la dama, il go e gli scacchi sono esempi di giochi a informazione perfetta, perché in ogni istante ciascun giocatore possiede la conoscenza completa del contesto attuale, delle strategie attuabili dall’avversario e delle mosse eseguite finora dall’avversario. Inoltre, sono giochi le cui regole sono in numero finito, immutabili, perfettamente note e formalizzabili matematicamente, e il cui unico obiettivo è molto semplice: vincere. Lo spazio delle possibili configurazioni è molto grande, ma ben definito, libero da ambiguità o interpretazioni. In una simile, ideale ambientazione, il self-play funziona alla grande.
E se pensassimo di applicare la stessa idea a un mondo più ampio di un semplice gioco da tavolo? Per esempio, il dominio generale coperto dai LLM. Qui l’obiettivo è decisamente più ambizioso: non si mira a vincere una partita in un particolare gioco da tavolo, ma a comprendere il linguaggio naturale e il mondo. In questo ambito, esiste qualche meccanismo simile al self-play? In un dominio così vasto, si può imparare “giocando contro sé stessi”? E se sì, i risultati sono buoni come nel ristretto ambito dei giochi?
Avrete già capito dove voglio andare a parare. Se addestriamo un modello linguistico sulla base di dataset di testi generati, almeno in parte, dallo stesso modello (o comunque da altri LLM), il modello, in un certo senso, “si sta guardando allo specchio”, perché abbiamo creato una sorta di loop (tra l’altro, nell’edizione di aprile della mia newsletter ho parlato di autoreferenza, strani anelli e cose simili, ma è uno dei miei temi preferiti e sicuramente ne parlerò ancora).
Secondo alcuni ricercatori, si tratta di un circolo vizioso più che virtuoso. Un po’ come il mitologico uroboro, il serpente che morde la propria coda.

Miniatura raffigurante un uroboro, da una copia, fatta nel 1478 da Theodoros Pelecanos,
di un perduto trattato alchemico attribuito a Sinesio di Cirene (370-413)
Alcuni autori ritengono questo “cannibalismo dei dati” responsabile di una progressiva degenerazione dei dati prodotti dai modelli. In questo scenario, l’algoritmo “impara il mondo senza guardare il mondo”, perché addestra il proprio modello utilizzando contenuti la cui origine non è completamente e genuinamente umana.
Molte ricerche hanno analizzato questo decadimento della qualità dei dati generati.
Per esempio, Ilia Shumailov e altri autori, nel paper The Curse of Recursion: Training on Generated Data Makes Models Forget (2023), profetizzano un esito catastrofico di questa tendenza: il cosiddetto model collapse.
In generale si parla di un fenomeno di perdita della parte “rara” dell’informazione, ovvero delle “code” delle distribuzioni di probabilità: insomma, un progressivo appiattimento e impoverimento, un esaurimento della varietà e della creatività, un aumento della prevedibilità. Gli errori statistici si accumulano, i dettagli rari si perdono, il modello dimentica la complessità, si standardizza, diventa più banale. Sembra quasi un equivalente computazionale della consanguineità biologica (inbreeding).
In un altro articolo dello stesso anno, The curious decline of linguistic diversity: training language models of synthetic text, Yanzhu Guo e altri indagano le conseguenze dell’addestrare modelli linguistici su testi sintetici generati dai loro stessi predecessori (pratica oggi sempre più diffusa nel mondo IA), osservando soprattutto le ricadute sulla diversità linguistica. Per eseguire questa valutazione, i ricercatori sono partiti da dati umani, con i quali hanno addestrato il Modello 1: i dati sintetici ottenuti da questo hanno addestrato il Modello 2, e così via per 6 iterazioni. I compiti consistevano in riassunti di notizie, generazione di abstract scientifici, scrittura di storie creative. La diversità linguistica, valutata mediante metriche lessicali, semantiche e sintattiche, è risultata progressivamente decrescente, soprattutto nei compiti che richiedono maggiore creatività.
Si dice spesso che ormai è difficile distinguere i dati generati da IA da quelli di origine umana, eppure, al tempo stesso, è frequente leggere, soprattutto sui social, testi di chiarissima derivazione artificiale, che esibiscono pattern retorici molto riconoscibili come firme IA, come antitesi correttive ("Non è X. È Y."), enumerazioni ternarie (“Un nuovo spazio Substack. Per riflettere. Per approfondire. Per osservare meglio la realtà.“) e altri stereotipi. Questi tic stilistici derivano dall’appiattimento linguistico prodotto dal cannibalismo ricorsivo dei dati? Non so se questa connessione sia stata dimostrata, ma non mi stupirei se uno studio portasse a questo risultato.
Pensando a questo fenomeno mi è venuto in mente il film d’animazione Yellow Submarine del 1968, diretto da George Dunning, con i Beatles come protagonisti nel ruolo di loro stessi. Nella sezione del film ambientata nel Sea of Monsters, i Beatles incontrano una strana creatura, il cosiddetto Suckophant, talvolta noto anche come “Mostro Aspirapolvere” (Vacuum Monster): un essere blu senza braccia e dotato di una specie di proboscide aspirante, con la quale cerca di inghiottire qualsiasi cosa gli capiti sotto tiro.
In alcune interviste, John Lennon ha rivelato di aver proposto personalmente l'idea del mostro al regista e ai disegnatori del film: l’ispirazione gli era arrivata osservando il modello di aspirapolvere Horace, utilizzato per la pulizia della sua piscina.
Nel film, dopo aver divorato tutti gli animali del mare, il Suckophant ingurgita anche il sottomarino giallo e poi addirittura l’intero universo attorno a lui.
Ed è in questo momento che arriva una delle scene più geniali e psichedeliche dell’intera pellicola. Ritrovatosi in un immenso, spiazzante vuoto bianco, e non trovando più nulla da ingerire, il mostro prende una decisione paradossale: punta la sua bocca-proboscide verso la sua stessa coda e inizia a risucchiare se stesso. Il Mostro Aspirapolvere si autodivora completamente (è in questo avverbio che risiede la meravigliosa assurdità della scena), lasciando lo schermo tutto bianco. Poi, miracolosamente, riappare il sottomarino dei Beatles e l’intero mondo.
Una scena tratta dal film "Yellow Submarine" (1968), © Apple Corps / United Artists.
La scena mi sembra una perfetta metafora visiva del model collapse. Il mostro rappresenta i modelli IA, con il loro disperato bisogno di fagocitare dati di training. Come il Suckophant, si nutrono inizialmente della realtà esterna, ovvero di dati autentici prodotti dall’uomo: così facendo i modelli crescono in piena salute. Una volta esauritasi la miniera dei dati genuinamente umani, i modelli si ritrovano senza nutrimento: è il fotogramma in cui il mostro è solo in mezzo allo schermo bianco. Scatta allora l'autoreferenzialità, l'autodivoramento, il cannibalismo, che porterebbe al loop tossico e al collasso.
Secondo alcuni studi, il problema affligge soprattutto i sistemi di IA generativa, per esempio quelli che producono testi, immagini, brani musicali e codice. Ciò non significa che altri ambiti dell’IA ne siano immuni, ma in molti casi è più semplice introdurre meccanismi di controllo esterni che limitano il degrado progressivo. Tra le strategie più efficaci posso citare la riduzione dei cicli ripetuti di addestramento su dati sintetici, l’ntroduzione di metriche esterne per mantenere elevata la qualità dei dati e soprattutto il continuo apporto, nella pipeline di addestramento, di freschi dati umani.
È esattamente questo il ponte che mi riporta al self-play. L’analogia tra le due situazioni è evidente: in entrambi i casi il modello “si guarda allo specchio”, superando la dipendenza dai dataset esterni di origine umana. Nel self-play il modello gioca direttamente contro sé stesso, generando dati sintetici relativi alle partite disputate: ripetendo il processo molte volte, può fare a meno di grandi dataset di incontri storici. Nel caso delle pipeline ricorsive di training, il modello genera i dati sui quali verrà addestrato successivamente: anche qui si può fare a meno di dati freschi di origine umana.
Ma l’analogia finisce qui. Tra i due c’è una differenza cruciale.
Nel training ricorsivo, se non si corregge il tiro iniettando almeno in parte dati di origine umana o introducendo misure indipendenti di qualità che mitighino il rischio di degradazione dei dati, si rischia di andare dritti verso il collasso: si perdono le code, la distribuzione si restringe progressivamente, i dati si appiattiscono.
Nel self-play, invece, la misura esterna di qualità è automaticamente presente, ed è il risultato della partita. Il fatto che un giocatore o l’altro vinca la partita è il dettaglio che fa la differenza, perché induce una pressione selettiva continua verso strategie che sono oggettivamente migliori. In questo modo, si crea sì un ciclo, ma è un ciclo virtuoso: partita dopo partita, il modello diventa genuinamente più forte, perché vengono premiate le mosse associate alla vittoria.
Il punto critico è che nei domini aperti come quelli in cui agiscono i grandi modelli non è sempre facile, o possibile, introdurre una misura esterna di qualità, una sorta di oracolo o giudice indipendente dal modello che possa verificare o validare l’output del modello. Ciò che nel caso dei giochi da tavolo è molto facile (basta considerare l’esito delle partite), in altri domini potrebbe costituire un problema.
Se l’ambito è la dimostrazione automatica di teoremi, si può introdurre un proof checker (spesso non umano, in ogni caso indipendente dal modello). Se parliamo di generazione di codice, può bastare un compilatore o qualcosa del genere che verifica se il codice è corretto o no.
Recentemente sono comparsi i cosiddetti reasoning model, che cercano di applicare l’idea ai LLM, nei casi in cui il modello debba risolvere un problema complicato (per esempio di matematica o di logica). Non potendo ricorrere a un arbitro esterno, viene sdoppiato il processo: da una parte si sviluppa una catena di pensieri (Chain of Thought) che esplora diverse soluzioni possibili, dall’altra viene creato un oracolo indipendente (anche se non del tutto esterno), chiamato reward model, che ha il compito di giudicare ogni singolo passaggio del ragionamento.
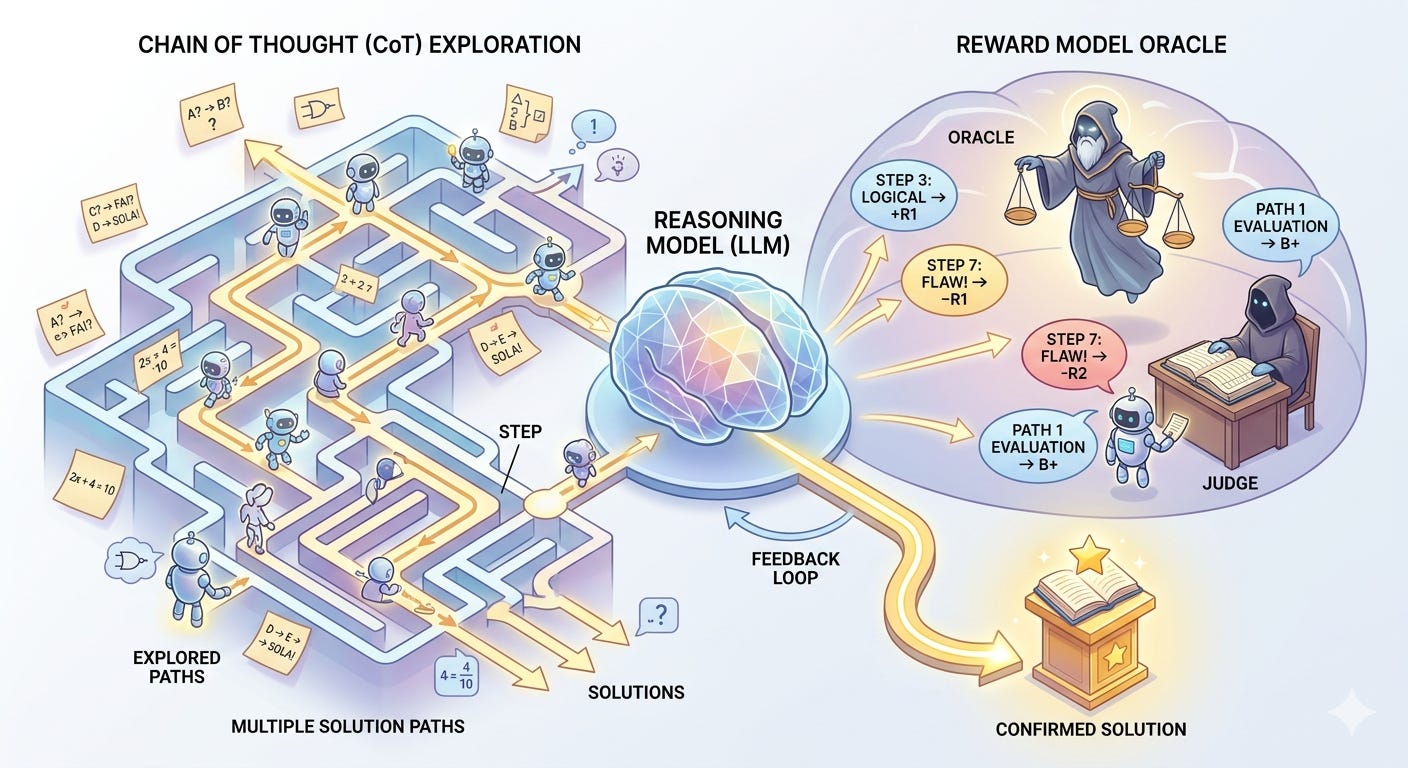
Ci sono ambiti in cui è complicato plasmare o trovare un giudice neutrale, e se a dare il voto è una componente troppo centrale del modello stesso si rischia una sorta di conflitto di interessi che può accelerare la degradazione dei dati. In questi casi ci si può salvare garantendo sempre, nelle fasi di addestramento, la presenza di dati freschi umani.
In definitiva, è come dicono gli psicologi: il narcisismo può essere buono o cattivo. Molto dipende dall’esistenza di un punto di riferimento esterno e indipendente che ci salvi dal solipsismo estremo. Altrimenti, come Narciso, rischiamo di annegare nel riflesso della nostra stessa immagine. O, peggio, di sparire nel vuoto bianco del Mostro Aspirapolvere.